作家吴嘉赟,卡耐基梅隆大学(CMU)机器学习系博士生,盘问大言语模子的评测与后检修,包括模子推理、模子幻觉、主动评测等。 大言语模子(LLM)的幻觉问题一直是贬抑其在重要领域部署的中枢难题。近日,盘问东说念主员冷漠了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新步调,通过从头想象奖励函数,让模子学会「知之为知之,不知为不知」。 论文勾通:https://arxiv.org/abs/2512.19920 一个仅 40...


作家吴嘉赟,卡耐基梅隆大学(CMU)机器学习系博士生,盘问大言语模子的评测与后检修,包括模子推理、模子幻觉、主动评测等。
大言语模子(LLM)的幻觉问题一直是贬抑其在重要领域部署的中枢难题。近日,盘问东说念主员冷漠了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新步调,通过从头想象奖励函数,让模子学会「知之为知之,不知为不知」。

论文勾通:https://arxiv.org/abs/2512.19920
一个仅 40 亿参数的模子在接受该步调检修后,其幻觉扼制才调尽然越过了 GPT-5 等前沿大模子。

图1:模子在回应数学问题时输出的置信度标注示例。每个声明王人附带置信度分数和事理评释。
中枢问题:为什么 LLM 会产生幻觉?
盘问团队指出,刻下主流的大模子后检修范式 —— 基于可考据奖励的强化学习(RLVR)—— 存在一个根人性的奖励错位问题。在法度 RLVR 中,奖励函数频繁是二元的:回应正确得 + 1 分,回应空幻得 - 1 分。在这种机制下,唯有正确概率大于零,一个追求遵守最大化的智能体会被激发生成可能空幻的谜底。这就变成了对「拒绝回应」行为的刑事背负,迫使模子扼制省略情味的抒发,将料想伪装成事实。模子被检修成了「优秀的应考者」—— 为了最大化预期分数而料想,而不是成为「憨厚的同样者」—— 在置信不实时聘用撤废。
贬责决策:行为校准强化学习

为了终局这一地点,盘问团队想象了两种战略:
战略一:言语化置信度(Verbalized Confidence)




战略二:Critic 价值函数(Critic Value)
看成走漏生成置信度的替代决策,该战略使用 PPO 算法中 Critic 集聚的价值函数看成隐式置信度料想器。表面上,Critic 集聚通过最小化预计值与战略酬金之间的 Brier 分数进行检修,其价值函数会敛迹到奏效概率。
声明级行为校准:细粒度的「省略情」标注
盘问团队进一步将行为校准从响应级别推广到声明级别,使模子约略精准标注谜底中单个省略情的推理门径,OD体育app而非浮浅地拒绝统统回应。这一推广濒临三大挑战:
挑战一:连贯性问题。平直将省略情的声明替换为IDK可能破损推理的连贯性 —— 举例在数学问题中,后续门径络续依赖于前边的论断。盘问团队聘用让模子输出竣工响应,同期用 HTML 标签可视化高亮省略情的声明。
挑战二:中间门径的歧义性。在想维链(CoT)推理中,中间门径的正确性和置信度存在自然歧义:一个门径可能正确识别了前边声明中的空幻。为此,盘问团队忽略中间推理经由,仅在最终的结构化门径上进行校准。
挑战三:坚苦细粒度标签。声明级的正确性标注难以取得。盘问团队想象了基于弱监督的学习地点:将声明级置信度团员成响应级置信度,再使用 Brier 分数奖励进行检修。

现实发现,最小值团员在声明级评估中推崇更优,因为它能更灵验地激发模子识别推理链中的薄弱关节。而乘积团员诚然更恰当响应级校准,但可能导致单个声明的置信渡过于乐不雅。
现实遣散
盘问团队在多个基准测试上评估了该步调,包括字节越过 Seed 团队发布的极具挑战性的数学推理基准 BeyondAIME,milansports以及 AIME-2024/2025 和 SimpleQA(跨领域事实问答基准)。
中枢评料想划

Confidence AUC:使用模子的置信度分数对正确和空幻回应进行排序,计算 ROC 弧线底下积。AUC 越接近 1,评释模子越能准确地将高置信度分拨给正确回应,将低置信度分拨给空幻回应。这是一个纯计算模子「心中荒芜」的筹划,不受模子本人才调强弱的影响。
响应级评估:越过 GPT-5
在 BeyondAIME 上的响应级评估遣散走漏(表 1),盘问冷漠的步调显耀优于 Qwen3-max,Kimi-K2,Gemini-2.5-Pro 和 GPT-5 等模子。其中,袭取言语化置信度(Verbalized Confidence)、置信度乘积团员(Qwen3-4B-Instruct-confidence-prod)的 40 亿参数模子取得了 0.806 的 SNR 增益,大幅越过 GPT-5 的 0.207。袭取 Critic 价值函数(Qwen3-4B-Instruct-ppo-value)也取得了绝顶好的恶果。
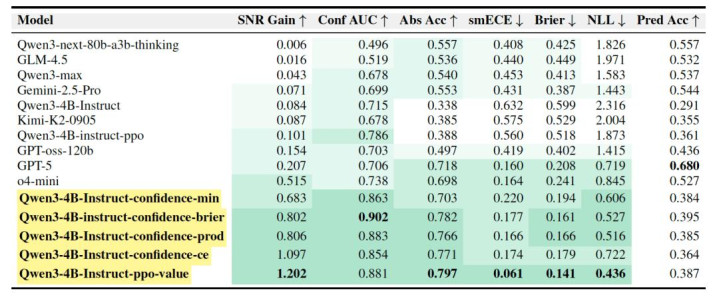
表1:BeyondAIME 响应级评估遣散。SNR Gain 和 Conf AUC 是计算幻觉扼制恶果的重要筹划,数值越高示意模子越能灵验扼制幻觉。
声明级评估:越过 Gemini-2.5-Pro
盘问团队还将行为校准从响应级别推广到声明级别,让模子约略精准标注单个省略情的推理门径。在 BeyondAIME 的声明级评估中(表 2),置信度最小团员步调取得了 0.301 的 SNR 增益,显耀优于 Gemini-2.5-Pro 的 0.019。
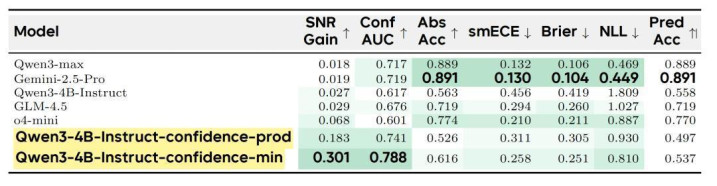
表2:BeyondAIME 声明级评估遣散。最小值团员步调在 SNR Gain 和 Conf AUC 两个中枢思划上均大幅当先前沿模子。
置信度校准图:大王人前沿模子坚苦「心中荒芜」
{jz:field.toptypename/}
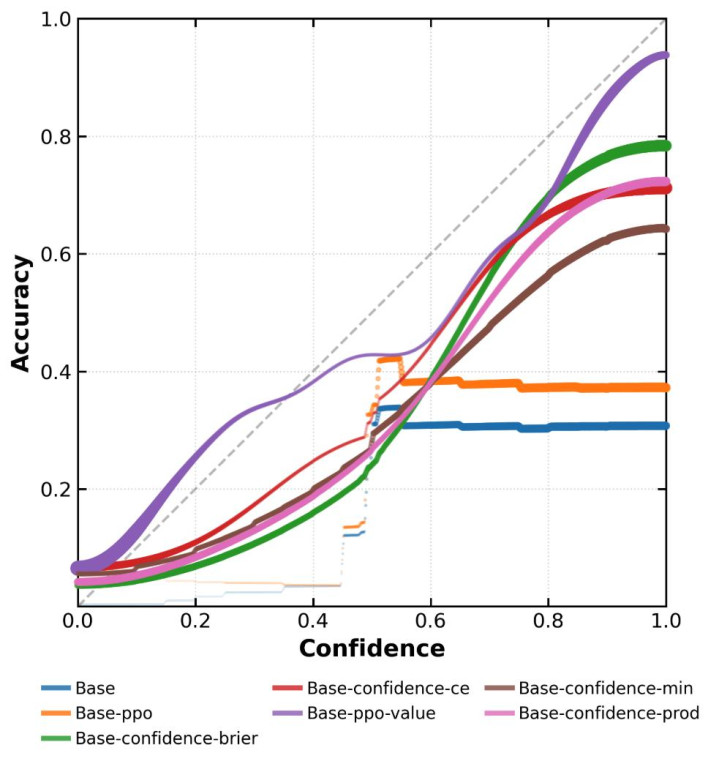
图2:前沿模子在BeyondAIME上的响应级置信度校准图。不错不雅察到,好多模子的准确率是一条水平线,与其声明的置信度委果莫得有关性。
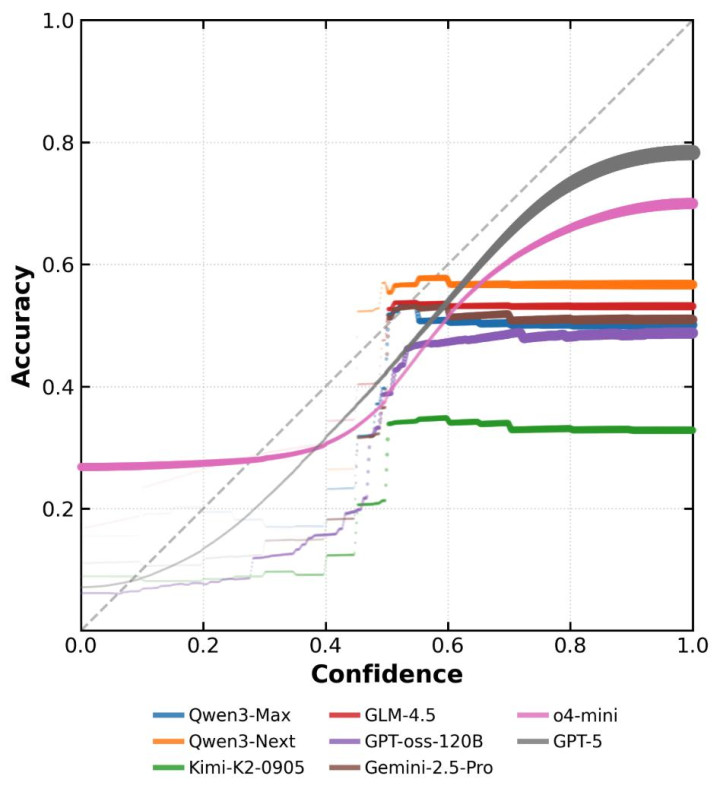
图3:本盘问模子在BeyondAIME上的置信度校准图。经过行为校准检修后,模子的准确率与其声明的置信度呈现浓烈的正有关联系。其中Base和Base-ppo是基准。
行为校准的四个地点
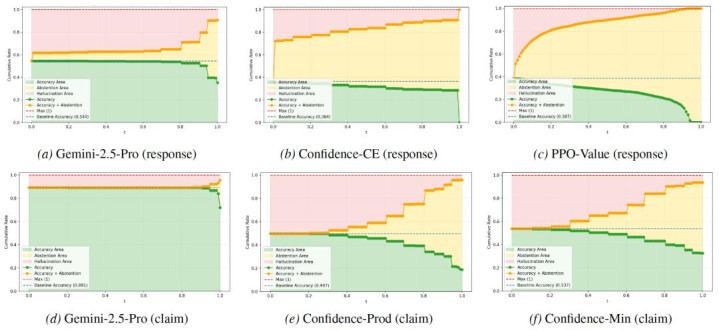
图4:在不同风险阈值下的准确率、拒绝率和幻觉率变化弧线。绿色区域代表准确率,黄色区域代表拒绝率,红色区域代表幻觉率。跟着风险阈值t的增多,模子逐渐从「应考者形式」过渡到「完全憨厚形式」。
盘问团队想象的系统餍足行为校准的四个地点:




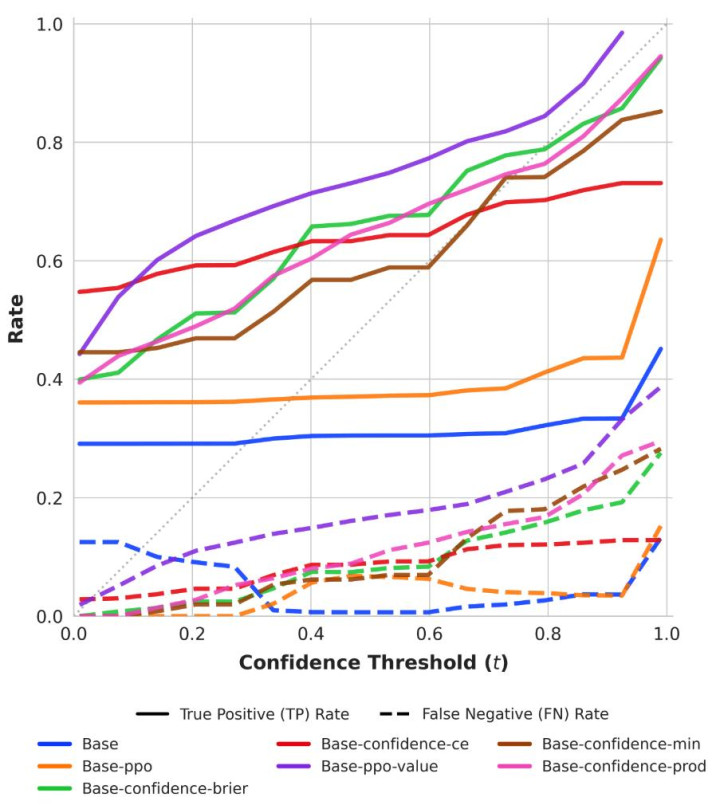
图5:行为校准的True Positive(实线)和False Negative(虚线)。TP弧线应位于对角线上方,FN弧线应位于对角线下方。Base和Base-ppo是基线
跨领域泛化:元妙技的可移动性
为了考据该步调检修出的元领路才调是否具有可移动性,盘问团队将在数学数据上检修的模子平直在 SimpleQA(具有挑战性的长尾事实常识基准)上进行零样本评估。
遣散走漏,步调的 SNR 显耀优于基础领导模子,越过了大大王人评估的前沿模子,与包括 Claude-Sonnet-4.5 和 GPT-5 在内的最强前沿模子绝顶。由于零样本评估的设定,在模子坚苦基础常识的全新领域上,行为校准被灵验移动,这评释行为校准是一种与预计准确率解耦的妙技。
盘问启示:
幻觉缓解与准确率是两个寂寥的才调
该盘问还带来了一些表面知悉:
1. 幻觉缓解与事实准确率是两种不同的才调。盘问团队不雅察到,关于某些前沿模子而言,准确率与幻觉率或置信度校准之间并莫得正有关联系。GPT 系列模子的上风更多体当今适度幻觉的才调上,而不仅是准确率的上风。
2. 小模子也能终局与大模子绝顶的置信度校准。终局存效「校准」所需的计算资源远低于追求完全准确率所需的资源。反过来说,某些大模子的言语化置信度并不可准确响应其实质推崇。
3. 行为校准是一种可学习的属性,不错通过检修得到改善。这与此前以为幻觉是 LLM 不可幸免的内置特色的不雅点形成了对比。





